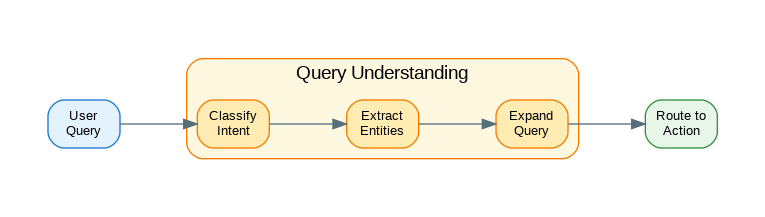
Introduction: Query understanding is the critical first step in building intelligent AI systems that respond appropriately to user requests. Before your system can retrieve relevant documents, call the right tools, or generate helpful responses, it needs to understand what the user actually wants. This involves intent classification (is this a question, command, or conversation?), entity extraction (what specific things are mentioned?), and query expansion (what related terms should we search for?). Poor query understanding leads to irrelevant results and frustrated users; excellent query understanding makes AI systems feel intuitive and helpful. This guide covers practical patterns for building query understanding pipelines: from rule-based classifiers to LLM-powered intent detection, entity extraction techniques, and query expansion strategies that improve retrieval accuracy.
Intent Classification
from dataclasses import dataclass, field
from typing import Any, Optional, List, Dict, Callable
from enum import Enum
import re
class IntentType(Enum):
"""Types of user intents."""
QUESTION = "question"
COMMAND = "command"
SEARCH = "search"
CONVERSATION = "conversation"
FEEDBACK = "feedback"
CLARIFICATION = "clarification"
@dataclass
class IntentResult:
"""Result of intent classification."""
intent: IntentType
confidence: float
sub_intent: str = None
metadata: dict = field(default_factory=dict)
class RuleBasedClassifier:
"""Rule-based intent classifier."""
def __init__(self):
self.rules: list[tuple[Callable[[str], bool], IntentType, float]] = []
self._register_default_rules()
def _register_default_rules(self):
"""Register default classification rules."""
# Question patterns
question_words = ["what", "who", "where", "when", "why", "how", "which", "can", "could", "would", "is", "are", "do", "does"]
def is_question(text: str) -> bool:
text_lower = text.lower().strip()
return (
text.endswith("?") or
any(text_lower.startswith(w + " ") for w in question_words)
)
self.rules.append((is_question, IntentType.QUESTION, 0.9))
# Command patterns
command_words = ["create", "delete", "update", "add", "remove", "set", "change", "make", "build", "generate", "show", "list", "find"]
def is_command(text: str) -> bool:
text_lower = text.lower().strip()
return any(text_lower.startswith(w + " ") for w in command_words)
self.rules.append((is_command, IntentType.COMMAND, 0.85))
# Search patterns
def is_search(text: str) -> bool:
text_lower = text.lower()
return (
"search for" in text_lower or
"find me" in text_lower or
"look up" in text_lower or
len(text.split()) <= 5 # Short queries are often searches
)
self.rules.append((is_search, IntentType.SEARCH, 0.7))
# Feedback patterns
feedback_words = ["thanks", "thank you", "great", "good", "bad", "wrong", "correct", "yes", "no"]
def is_feedback(text: str) -> bool:
text_lower = text.lower().strip()
return any(text_lower.startswith(w) for w in feedback_words)
self.rules.append((is_feedback, IntentType.FEEDBACK, 0.8))
def classify(self, query: str) -> IntentResult:
"""Classify query intent."""
for rule, intent, confidence in self.rules:
if rule(query):
return IntentResult(
intent=intent,
confidence=confidence
)
# Default to conversation
return IntentResult(
intent=IntentType.CONVERSATION,
confidence=0.5
)
class EmbeddingClassifier:
"""Embedding-based intent classifier."""
def __init__(self, embedding_model: Any):
self.embedding_model = embedding_model
self.intent_embeddings: dict[IntentType, list[float]] = {}
self.examples: dict[IntentType, list[str]] = {}
def add_examples(self, intent: IntentType, examples: list[str]):
"""Add training examples for intent."""
self.examples[intent] = examples
async def train(self):
"""Train classifier on examples."""
import numpy as np
for intent, examples in self.examples.items():
embeddings = await self.embedding_model.embed_batch(examples)
# Average embeddings for intent
self.intent_embeddings[intent] = np.mean(embeddings, axis=0).tolist()
async def classify(self, query: str) -> IntentResult:
"""Classify query using embeddings."""
import numpy as np
query_embedding = await self.embedding_model.embed(query)
best_intent = None
best_similarity = -1
for intent, intent_embedding in self.intent_embeddings.items():
similarity = self._cosine_similarity(query_embedding, intent_embedding)
if similarity > best_similarity:
best_similarity = similarity
best_intent = intent
return IntentResult(
intent=best_intent,
confidence=best_similarity
)
def _cosine_similarity(self, a: list, b: list) -> float:
import numpy as np
a = np.array(a)
b = np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
class LLMClassifier:
"""LLM-based intent classifier."""
def __init__(self, llm_client: Any):
self.llm = llm_client
self.intents: list[dict] = []
def register_intent(
self,
intent: str,
description: str,
examples: list[str]
):
"""Register an intent."""
self.intents.append({
"intent": intent,
"description": description,
"examples": examples
})
async def classify(self, query: str) -> IntentResult:
"""Classify query using LLM."""
intent_descriptions = "\n".join([
f"- {i['intent']}: {i['description']} (e.g., {', '.join(i['examples'][:2])})"
for i in self.intents
])
prompt = f"""Classify the following user query into one of these intents:
{intent_descriptions}
Query: "{query}"
Respond with JSON:
{{"intent": "", "confidence": <0.0-1.0>, "reasoning": ""}}
JSON:"""
response = await self.llm.generate(prompt)
try:
import json
data = json.loads(response)
return IntentResult(
intent=IntentType(data["intent"]) if data["intent"] in [i.value for i in IntentType] else IntentType.CONVERSATION,
confidence=data.get("confidence", 0.8),
metadata={"reasoning": data.get("reasoning", "")}
)
except:
return IntentResult(
intent=IntentType.CONVERSATION,
confidence=0.5
) Entity Extraction
from dataclasses import dataclass
from typing import Any, Optional, List
import re
@dataclass
class Entity:
"""An extracted entity."""
text: str
entity_type: str
start: int
end: int
confidence: float
normalized: str = None
class PatternEntityExtractor:
"""Pattern-based entity extraction."""
def __init__(self):
self.patterns: dict[str, list[re.Pattern]] = {}
self._register_default_patterns()
def _register_default_patterns(self):
"""Register default entity patterns."""
# Date patterns
self.patterns["DATE"] = [
re.compile(r'\b\d{1,2}/\d{1,2}/\d{2,4}\b'),
re.compile(r'\b\d{4}-\d{2}-\d{2}\b'),
re.compile(r'\b(today|tomorrow|yesterday)\b', re.I),
re.compile(r'\b(monday|tuesday|wednesday|thursday|friday|saturday|sunday)\b', re.I),
re.compile(r'\b(january|february|march|april|may|june|july|august|september|october|november|december)\s+\d{1,2}(,?\s+\d{4})?\b', re.I)
]
# Time patterns
self.patterns["TIME"] = [
re.compile(r'\b\d{1,2}:\d{2}(\s*(am|pm))?\b', re.I),
re.compile(r'\b\d{1,2}\s*(am|pm)\b', re.I)
]
# Number patterns
self.patterns["NUMBER"] = [
re.compile(r'\b\d+(\.\d+)?\b'),
re.compile(r'\$\d+(\.\d{2})?'),
re.compile(r'\b\d+%\b')
]
# Email patterns
self.patterns["EMAIL"] = [
re.compile(r'\b[\w.-]+@[\w.-]+\.\w+\b')
]
# URL patterns
self.patterns["URL"] = [
re.compile(r'https?://\S+')
]
def extract(self, text: str) -> list[Entity]:
"""Extract entities from text."""
entities = []
for entity_type, patterns in self.patterns.items():
for pattern in patterns:
for match in pattern.finditer(text):
entities.append(Entity(
text=match.group(),
entity_type=entity_type,
start=match.start(),
end=match.end(),
confidence=0.9
))
# Remove overlapping entities (keep longer ones)
entities = self._remove_overlaps(entities)
return entities
def _remove_overlaps(self, entities: list[Entity]) -> list[Entity]:
"""Remove overlapping entities."""
if not entities:
return []
# Sort by start position, then by length (descending)
entities.sort(key=lambda e: (e.start, -(e.end - e.start)))
result = [entities[0]]
for entity in entities[1:]:
last = result[-1]
# Check for overlap
if entity.start >= last.end:
result.append(entity)
return result
class LLMEntityExtractor:
"""LLM-based entity extraction."""
def __init__(self, llm_client: Any):
self.llm = llm_client
self.entity_types: list[dict] = []
def register_entity_type(
self,
name: str,
description: str,
examples: list[str]
):
"""Register an entity type."""
self.entity_types.append({
"name": name,
"description": description,
"examples": examples
})
async def extract(self, text: str) -> list[Entity]:
"""Extract entities using LLM."""
type_descriptions = "\n".join([
f"- {t['name']}: {t['description']} (e.g., {', '.join(t['examples'][:3])})"
for t in self.entity_types
])
prompt = f"""Extract entities from the following text.
Entity types to extract:
{type_descriptions}
Text: "{text}"
Respond with JSON array:
[{{"text": "", "type": " ", "normalized": ""}}]
JSON:"""
response = await self.llm.generate(prompt)
try:
import json
data = json.loads(response)
entities = []
for item in data:
# Find position in text
start = text.find(item["text"])
if start >= 0:
entities.append(Entity(
text=item["text"],
entity_type=item["type"],
start=start,
end=start + len(item["text"]),
confidence=0.8,
normalized=item.get("normalized")
))
return entities
except:
return []
class HybridEntityExtractor:
"""Combine pattern and LLM extraction."""
def __init__(
self,
pattern_extractor: PatternEntityExtractor,
llm_extractor: LLMEntityExtractor
):
self.pattern = pattern_extractor
self.llm = llm_extractor
async def extract(self, text: str) -> list[Entity]:
"""Extract entities using both methods."""
# Get pattern-based entities (fast, high precision)
pattern_entities = self.pattern.extract(text)
# Get LLM entities (slower, better recall)
llm_entities = await self.llm.extract(text)
# Merge results
all_entities = pattern_entities + llm_entities
# Deduplicate
seen = set()
unique = []
for entity in all_entities:
key = (entity.text, entity.entity_type)
if key not in seen:
seen.add(key)
unique.append(entity)
return unique Query Expansion
from dataclasses import dataclass
from typing import Any, Optional, List
@dataclass
class ExpandedQuery:
"""An expanded query."""
original: str
expanded: str
synonyms: list[str]
related_terms: list[str]
reformulations: list[str]
class SynonymExpander:
"""Expand queries with synonyms."""
def __init__(self):
self.synonyms: dict[str, list[str]] = {}
self._load_default_synonyms()
def _load_default_synonyms(self):
"""Load default synonym mappings."""
self.synonyms = {
"create": ["make", "build", "generate", "produce"],
"delete": ["remove", "erase", "destroy", "eliminate"],
"update": ["modify", "change", "edit", "revise"],
"find": ["search", "locate", "discover", "lookup"],
"show": ["display", "present", "reveal", "list"],
"fast": ["quick", "rapid", "speedy", "swift"],
"slow": ["sluggish", "delayed", "gradual"],
"big": ["large", "huge", "massive", "enormous"],
"small": ["tiny", "little", "compact", "miniature"],
"good": ["excellent", "great", "quality", "superior"],
"bad": ["poor", "inferior", "subpar", "deficient"]
}
def expand(self, query: str) -> list[str]:
"""Expand query with synonyms."""
words = query.lower().split()
expansions = [query]
for i, word in enumerate(words):
if word in self.synonyms:
for synonym in self.synonyms[word]:
new_words = words.copy()
new_words[i] = synonym
expansions.append(" ".join(new_words))
return expansions
class LLMQueryExpander:
"""LLM-based query expansion."""
def __init__(self, llm_client: Any):
self.llm = llm_client
async def expand(self, query: str) -> ExpandedQuery:
"""Expand query using LLM."""
prompt = f"""Expand this search query to improve retrieval.
Original query: "{query}"
Generate:
1. 3-5 synonyms for key terms
2. 3-5 related terms that might appear in relevant documents
3. 2-3 alternative ways to phrase this query
Respond with JSON:
{{
"synonyms": ["term1", "term2", ...],
"related_terms": ["term1", "term2", ...],
"reformulations": ["query1", "query2", ...]
}}
JSON:"""
response = await self.llm.generate(prompt)
try:
import json
data = json.loads(response)
return ExpandedQuery(
original=query,
expanded=self._build_expanded_query(query, data),
synonyms=data.get("synonyms", []),
related_terms=data.get("related_terms", []),
reformulations=data.get("reformulations", [])
)
except:
return ExpandedQuery(
original=query,
expanded=query,
synonyms=[],
related_terms=[],
reformulations=[]
)
def _build_expanded_query(self, original: str, data: dict) -> str:
"""Build expanded query string."""
terms = [original]
terms.extend(data.get("synonyms", [])[:3])
terms.extend(data.get("related_terms", [])[:2])
return " ".join(terms)
class HypotheticalDocumentExpander:
"""HyDE - Generate hypothetical document for expansion."""
def __init__(self, llm_client: Any):
self.llm = llm_client
async def expand(self, query: str) -> str:
"""Generate hypothetical document that would answer the query."""
prompt = f"""Write a short passage (2-3 sentences) that would be a perfect answer to this query.
Write as if you're writing a document that contains the answer, not answering directly.
Query: "{query}"
Passage:"""
return await self.llm.generate(prompt)
class QueryRewriter:
"""Rewrite queries for better retrieval."""
def __init__(self, llm_client: Any):
self.llm = llm_client
async def rewrite(
self,
query: str,
context: str = None
) -> str:
"""Rewrite query for retrieval."""
context_section = f"\nConversation context: {context}" if context else ""
prompt = f"""Rewrite this query to be more specific and searchable.
Remove pronouns and ambiguous references.
Make the query self-contained.{context_section}
Original query: "{query}"
Rewritten query:"""
return await self.llm.generate(prompt)
async def decompose(self, query: str) -> list[str]:
"""Decompose complex query into sub-queries."""
prompt = f"""Break down this complex query into simpler sub-queries.
Each sub-query should be answerable independently.
Query: "{query}"
Respond with JSON array of sub-queries:
["sub-query 1", "sub-query 2", ...]
JSON:"""
response = await self.llm.generate(prompt)
try:
import json
return json.loads(response)
except:
return [query]Query Understanding Pipeline
from dataclasses import dataclass
from typing import Any, Optional, List
@dataclass
class QueryUnderstanding:
"""Complete query understanding result."""
original_query: str
intent: IntentResult
entities: list[Entity]
expanded_query: ExpandedQuery
rewritten_query: str
sub_queries: list[str]
metadata: dict
class QueryUnderstandingPipeline:
"""Complete query understanding pipeline."""
def __init__(
self,
intent_classifier: Any,
entity_extractor: Any,
query_expander: Any,
query_rewriter: Any
):
self.classifier = intent_classifier
self.extractor = entity_extractor
self.expander = query_expander
self.rewriter = query_rewriter
async def understand(
self,
query: str,
context: str = None
) -> QueryUnderstanding:
"""Run full query understanding pipeline."""
import asyncio
# Run classification and extraction in parallel
intent_task = asyncio.create_task(
self._classify_intent(query)
)
entity_task = asyncio.create_task(
self._extract_entities(query)
)
intent = await intent_task
entities = await entity_task
# Rewrite query if needed
rewritten = query
if context or intent.intent == IntentType.CLARIFICATION:
rewritten = await self.rewriter.rewrite(query, context)
# Expand query for search intents
expanded = None
if intent.intent in [IntentType.SEARCH, IntentType.QUESTION]:
expanded = await self.expander.expand(rewritten)
else:
expanded = ExpandedQuery(
original=query,
expanded=query,
synonyms=[],
related_terms=[],
reformulations=[]
)
# Decompose complex queries
sub_queries = [query]
if len(query.split()) > 10:
sub_queries = await self.rewriter.decompose(query)
return QueryUnderstanding(
original_query=query,
intent=intent,
entities=entities,
expanded_query=expanded,
rewritten_query=rewritten,
sub_queries=sub_queries,
metadata={
"has_context": context is not None,
"entity_count": len(entities)
}
)
async def _classify_intent(self, query: str) -> IntentResult:
"""Classify intent with fallback."""
try:
if hasattr(self.classifier, 'classify'):
result = self.classifier.classify(query)
if asyncio.iscoroutine(result):
return await result
return result
except:
pass
return IntentResult(
intent=IntentType.CONVERSATION,
confidence=0.5
)
async def _extract_entities(self, query: str) -> list[Entity]:
"""Extract entities with fallback."""
try:
result = self.extractor.extract(query)
if asyncio.iscoroutine(result):
return await result
return result
except:
return []
class QueryRouter:
"""Route queries based on understanding."""
def __init__(self):
self.routes: dict[IntentType, Callable] = {}
def register_route(
self,
intent: IntentType,
handler: Callable
):
"""Register route handler."""
self.routes[intent] = handler
async def route(
self,
understanding: QueryUnderstanding
) -> Any:
"""Route query to appropriate handler."""
handler = self.routes.get(understanding.intent.intent)
if handler:
result = handler(understanding)
if asyncio.iscoroutine(result):
return await result
return result
# Default handler
return {
"action": "default",
"query": understanding.original_query
}Production Query Service
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Optional, List, Dict
app = FastAPI()
class QueryRequest(BaseModel):
query: str
context: Optional[str] = None
expand: bool = True
extract_entities: bool = True
class IntentRequest(BaseModel):
query: str
class EntityRequest(BaseModel):
text: str
entity_types: Optional[List[str]] = None
# Initialize components
rule_classifier = RuleBasedClassifier()
pattern_extractor = PatternEntityExtractor()
synonym_expander = SynonymExpander()
@app.post("/v1/understand")
async def understand_query(request: QueryRequest) -> dict:
"""Full query understanding."""
result = {
"original_query": request.query,
"intent": None,
"entities": [],
"expanded": None
}
# Classify intent
intent = rule_classifier.classify(request.query)
result["intent"] = {
"type": intent.intent.value,
"confidence": intent.confidence
}
# Extract entities
if request.extract_entities:
entities = pattern_extractor.extract(request.query)
result["entities"] = [
{
"text": e.text,
"type": e.entity_type,
"start": e.start,
"end": e.end
}
for e in entities
]
# Expand query
if request.expand:
expansions = synonym_expander.expand(request.query)
result["expanded"] = {
"queries": expansions,
"count": len(expansions)
}
return result
@app.post("/v1/classify")
async def classify_intent(request: IntentRequest) -> dict:
"""Classify query intent."""
intent = rule_classifier.classify(request.query)
return {
"query": request.query,
"intent": intent.intent.value,
"confidence": intent.confidence,
"metadata": intent.metadata
}
@app.post("/v1/entities")
async def extract_entities(request: EntityRequest) -> list[dict]:
"""Extract entities from text."""
entities = pattern_extractor.extract(request.text)
# Filter by type if specified
if request.entity_types:
entities = [e for e in entities if e.entity_type in request.entity_types]
return [
{
"text": e.text,
"type": e.entity_type,
"start": e.start,
"end": e.end,
"confidence": e.confidence,
"normalized": e.normalized
}
for e in entities
]
@app.post("/v1/expand")
async def expand_query(query: str) -> dict:
"""Expand query with synonyms."""
expansions = synonym_expander.expand(query)
return {
"original": query,
"expansions": expansions,
"count": len(expansions)
}
@app.get("/health")
async def health():
return {"status": "healthy"}References
- spaCy NER: https://spacy.io/usage/linguistic-features#named-entities
- HuggingFace NER: https://huggingface.co/tasks/token-classification
- Query Expansion: https://en.wikipedia.org/wiki/Query_expansion
- HyDE Paper: https://arxiv.org/abs/2212.10496
- LangChain Query Analysis: https://python.langchain.com/docs/use_cases/query_analysis/
Conclusion
Query understanding is the foundation of intelligent AI systems. Start with rule-based classifiers for common patterns—they’re fast, predictable, and don’t require API calls. Layer in embedding-based classification for nuanced intent detection and LLM-based classification for complex cases. Entity extraction should combine pattern matching for structured data (dates, emails, numbers) with LLM extraction for domain-specific entities. Query expansion significantly improves retrieval: synonyms catch vocabulary mismatches, related terms improve recall, and HyDE generates hypothetical documents that bridge the gap between queries and documents. For conversational systems, query rewriting resolves pronouns and ambiguous references using conversation context. Build your pipeline to run classification and extraction in parallel for better latency. Monitor classification accuracy and entity extraction precision in production—these metrics directly impact downstream retrieval and response quality. The goal is to transform ambiguous user input into structured, searchable queries that your retrieval system can handle effectively.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.