MLflow has emerged as the leading open-source platform for managing the complete machine learning lifecycle, from experimentation through deployment. This comprehensive guide explores production MLOps patterns using MLflow, covering experiment tracking, model registry, automated deployment pipelines, and monitoring strategies.
After implementing MLflow across multiple enterprise ML platforms, I’ve found that success depends on establishing consistent tracking conventions, implementing robust model versioning, and integrating with existing CI/CD infrastructure. Organizations should adopt MLflow incrementally, starting with experiment tracking for immediate visibility, then expanding to model registry and automated deployment as ML maturity grows.
MLflow Platform Architecture
Before diving into specific patterns, let’s understand the complete MLflow architecture and how its components work together to enable end-to-end MLOps:
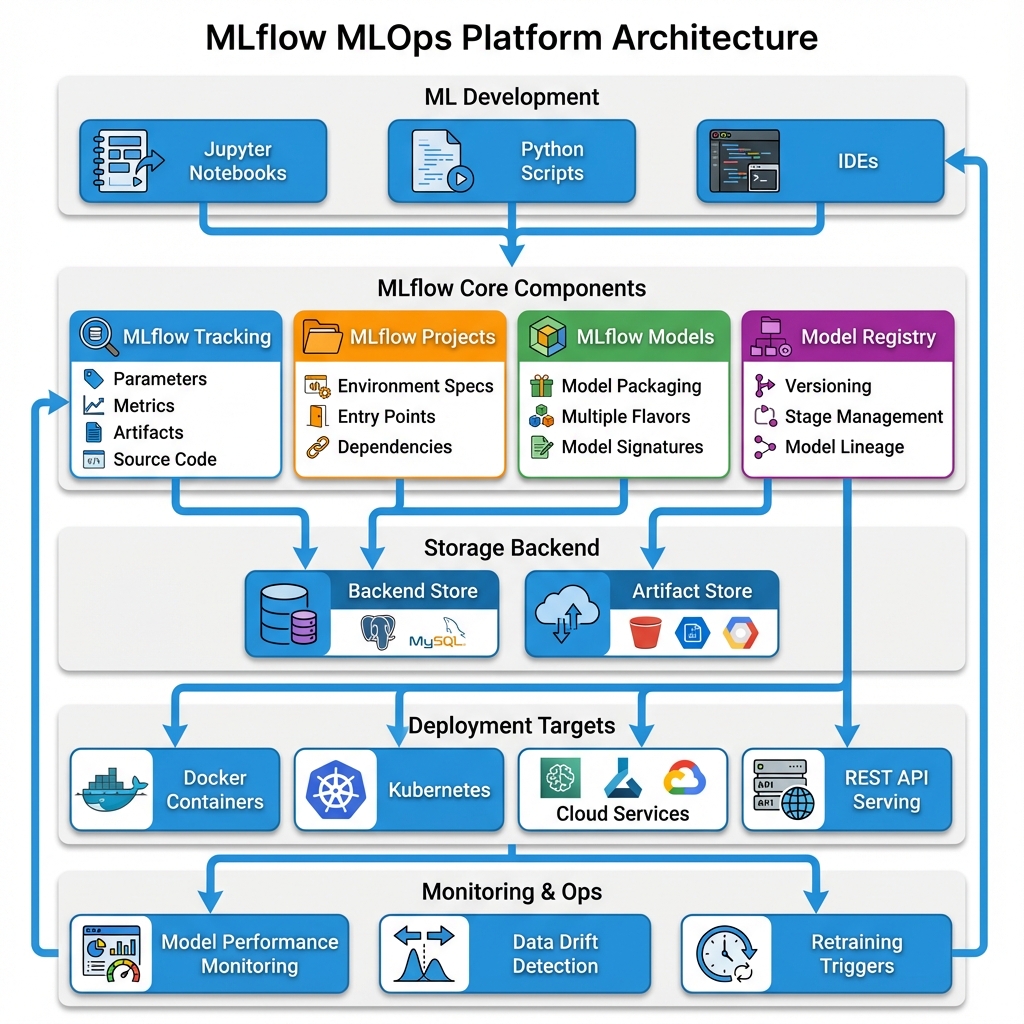
MLflow’s architecture consists of four core components that work together: Tracking for experiment management, Projects for reproducible runs, Models for packaging and deployment, and the Model Registry for version control and governance. This modular design allows teams to adopt components incrementally based on their MLOps maturity.
Experiment Tracking for Reproducibility
Reproducibility forms the foundation of reliable machine learning. MLflow’s tracking component captures parameters, metrics, artifacts, and source code for every experiment run. This comprehensive logging enables teams to understand what worked, why it worked, and how to reproduce results months or years later.
Without systematic tracking, ML projects devolve into chaos where no one knows which model version is in production or how it was trained. Structured experiment organization improves team collaboration and knowledge sharing.
Best Practices for Experiment Tracking
- Create logical experiment groupings – Organize by project, model type, or business domain
- Use consistent naming conventions – Standardize parameter and metric names across experiments
- Tag runs with metadata – Include dataset versions, feature sets, and business context
- Log comprehensive artifacts – Include preprocessing pipelines, feature transformers, and evaluation reports
- Capture environment specifications – Log everything needed to reproduce results
Artifact management extends beyond model files. MLflow’s artifact storage integrates with S3, Azure Blob, and GCS for scalable, durable storage of large artifacts.
Model Registry for Governance
The Model Registry provides centralized model management with versioning, stage transitions, and access control. Register models after successful training runs to create an auditable history of model evolution. Each registered version links back to the experiment run that produced it, maintaining complete lineage from data to deployment.
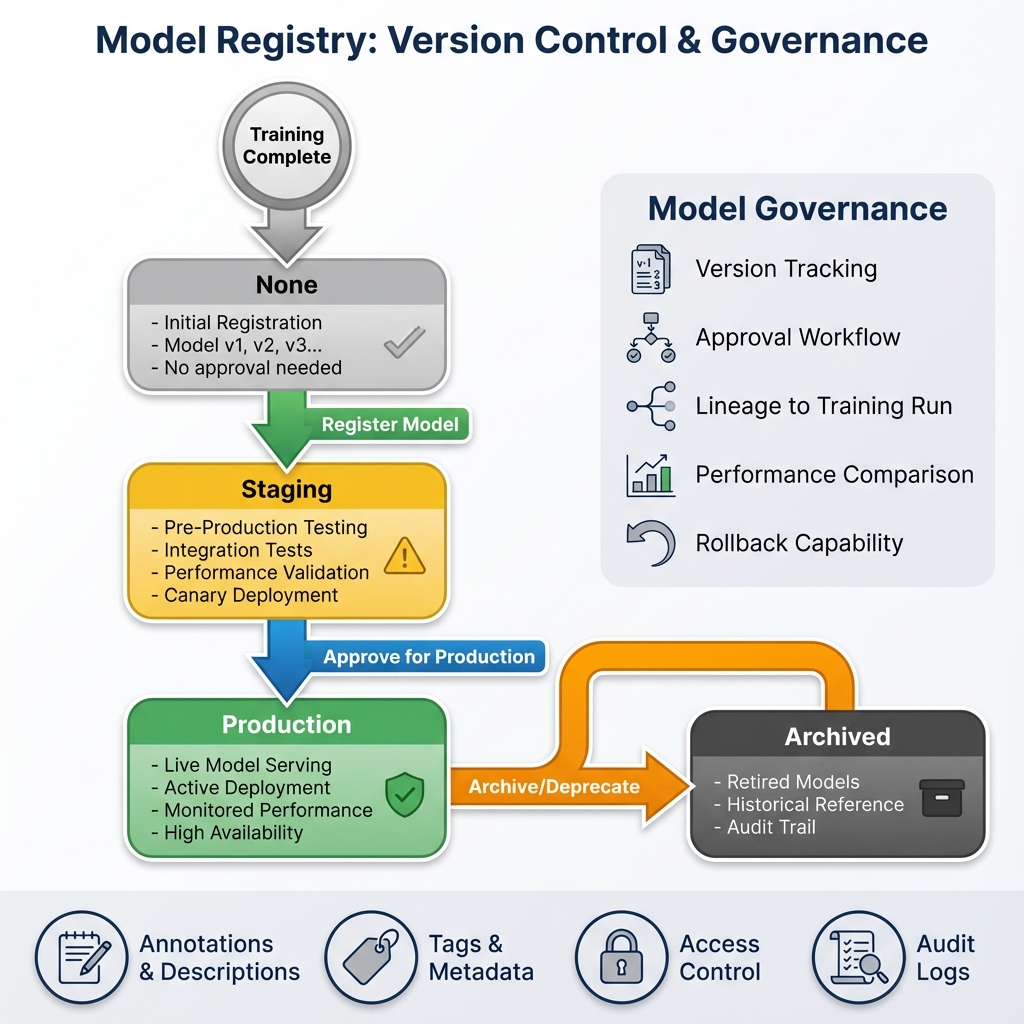
Stage Transitions & Governance
Stage transitions implement governance workflows for model promotion. Models progress through stages—None, Staging, Production, Archived—with each transition logged and optionally requiring approval. This workflow prevents untested models from reaching production while enabling rapid iteration in development environments.
- None: Initial registration, no approval needed
- Staging: Pre-production testing, integration tests, performance validation
- Production: Live model serving with monitored performance and high availability
- Archived: Retired models maintained for historical reference and audit trails
Model annotations capture institutional knowledge about model behavior, limitations, and intended use cases. Document model performance characteristics, known failure modes, and operational requirements. These annotations become invaluable during incident response and model selection for new use cases.
Production MLOps Pipeline
Building a production-grade MLOps pipeline requires orchestrating multiple stages from data preparation through deployment and monitoring. Here’s how MLflow components integrate across the entire lifecycle:
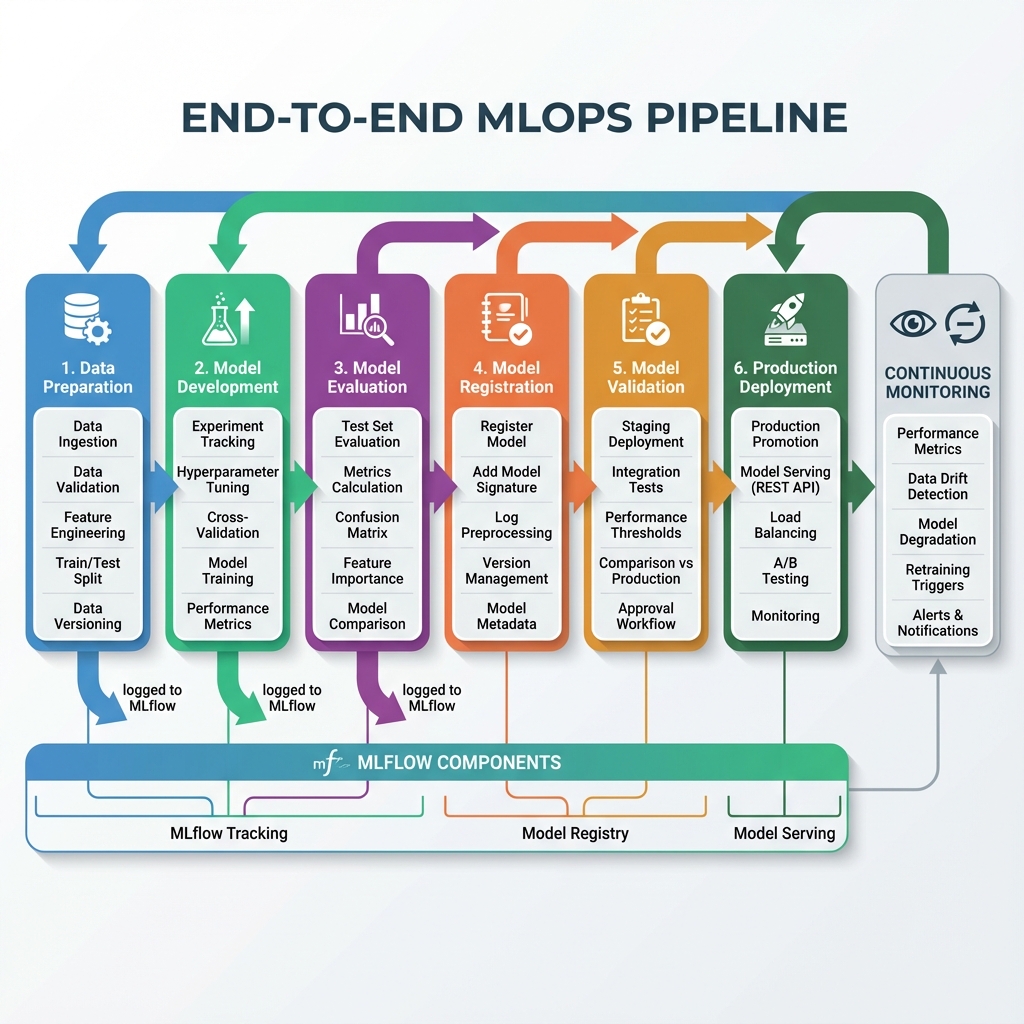
Pipeline Stages Explained
- Data Preparation: Ingest, validate, engineer features, and version datasets
- Model Development: Track experiments, tune hyperparameters, and log metrics
- Model Evaluation: Calculate comprehensive metrics and compare performance
- Model Registration: Register models with signatures and preprocessing artifacts
- Model Validation: Test in staging, validate thresholds, and approve for production
- Production Deployment: Serve models via REST API with A/B testing and monitoring
Each stage integrates with MLflow components: Tracking spans data preparation through evaluation, Model Registry manages registration through deployment, and Model Serving handles production traffic.
Automated CI/CD for ML Models
Continuous integration for ML extends traditional CI practices to include data validation, model training, and performance testing. Trigger training pipelines on code changes, data updates, or scheduled intervals. Validate that models meet minimum performance thresholds before allowing merges. This automation catches regressions early and ensures consistent model quality.

CI/CD Best Practices
Continuous deployment for ML requires careful orchestration of model promotion, canary releases, and rollback capabilities:
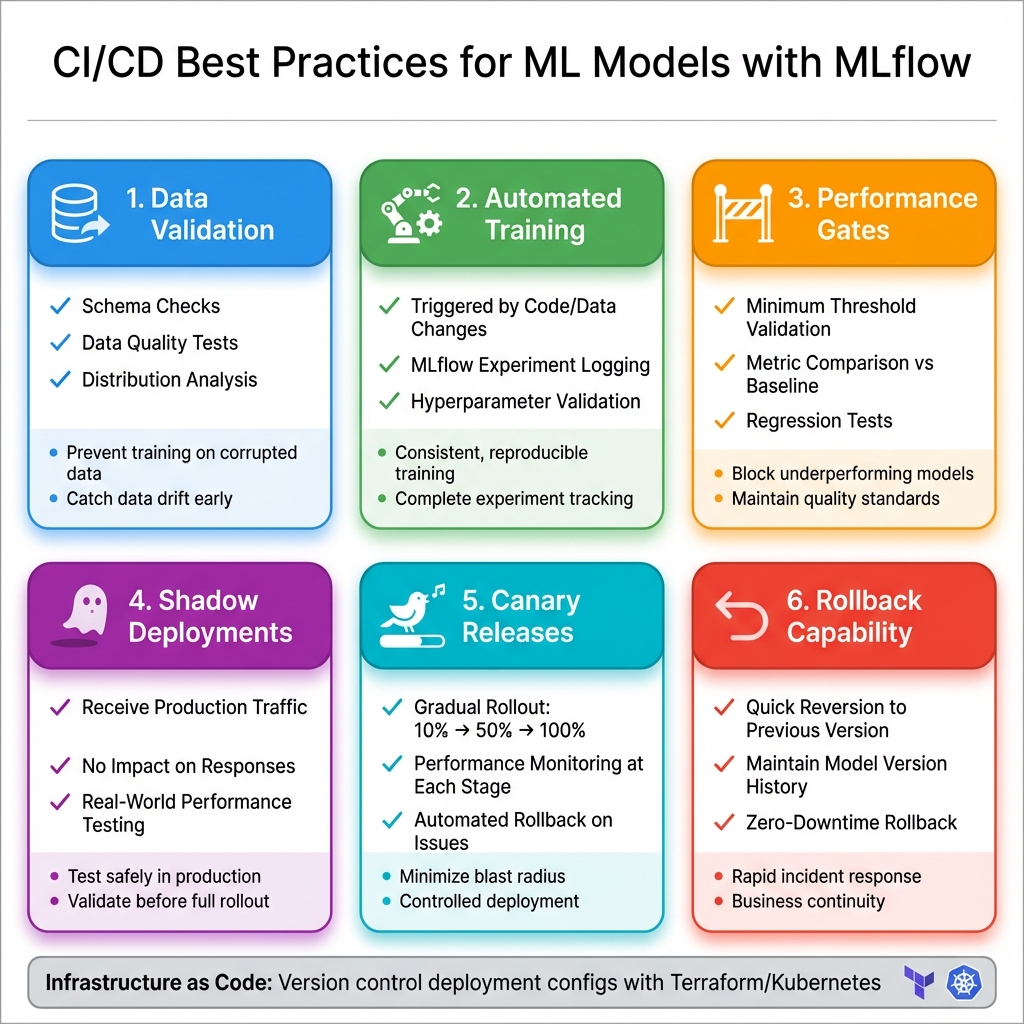
- Data Validation: Schema checks, quality tests, and distribution analysis
- Automated Training: Triggered by code/data changes with MLflow experiment logging
- Performance Gates: Minimum threshold validation before promotion
- Shadow Deployments: New models receive production traffic without affecting responses
- Canary Releases: Gradual rollout (10% → 50% → 100%) with performance monitoring
- Rollback Capability: Quick reversion to previous versions when issues arise
Infrastructure as code for ML environments ensures reproducible deployments across development, staging, and production. Define model serving infrastructure using Terraform or Kubernetes manifests. Version control these definitions alongside model code to maintain consistency between model versions and their deployment configurations.
Key Takeaways and Best Practices
MLflow provides the foundation for mature MLOps practices, enabling reproducibility, governance, and automated deployment. Here’s how to succeed:
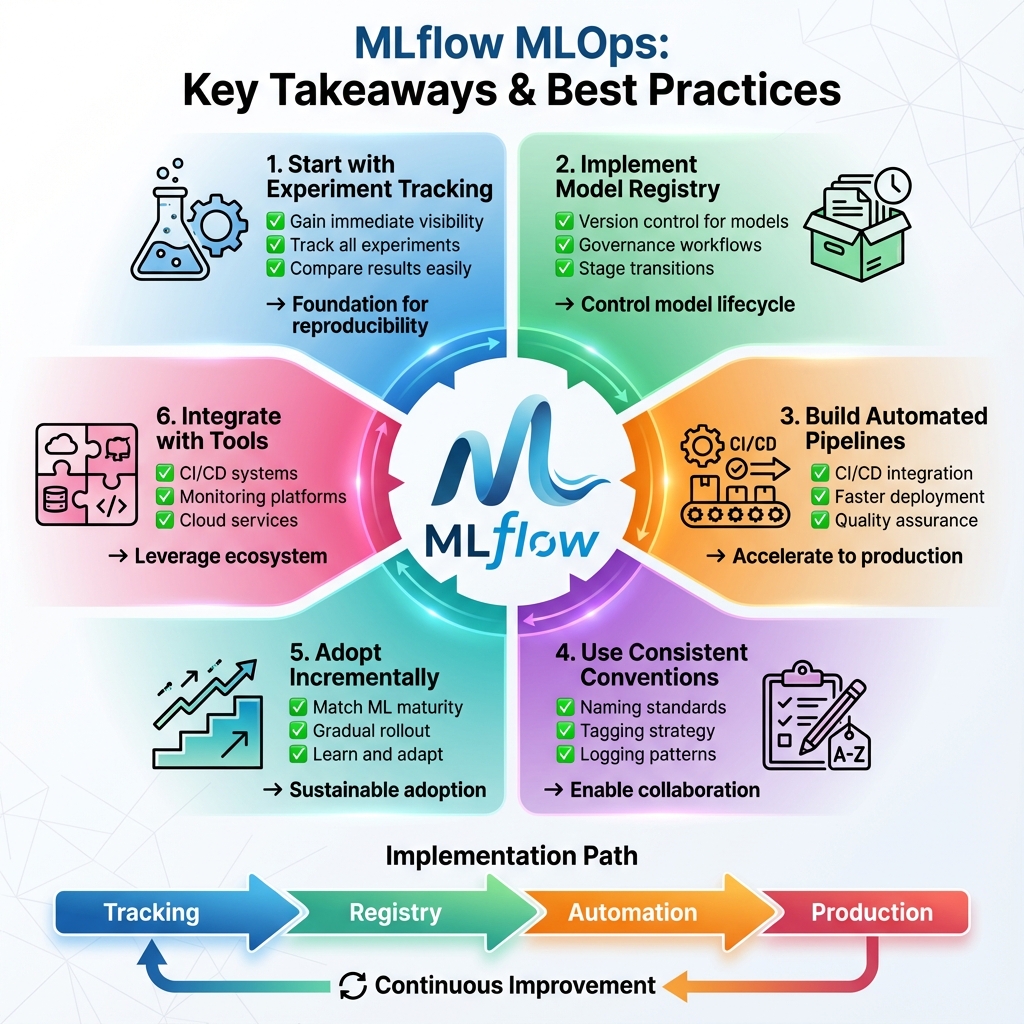
- ✅ Start with experiment tracking – Gain immediate visibility into model development
- ✅ Implement model registry – Establish governance workflows and version control
- ✅ Build automated pipelines – Accelerate time-to-production while maintaining quality
- ✅ Use consistent conventions – Standardize naming, tagging, and logging across teams
- ✅ Adopt incrementally – Match MLflow adoption to your organization’s ML maturity
- ✅ Integrate with existing tools – Connect MLflow to your CI/CD, monitoring, and deployment infrastructure
The implementation patterns demonstrated in this article establish a foundation for production MLOps. Customize tracking conventions, validation thresholds, and deployment strategies for your organization’s specific requirements.
What’s Next: In upcoming articles, we’ll explore feature engineering at scale, building on these MLOps foundations to create robust feature pipelines that integrate seamlessly with MLflow tracking and deployment.
Have you implemented MLflow in production? Share your experiences and challenges on GitHub or LinkedIn.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.