Watching the AWS re:Invent 2024 announcements online, Bedrock Multi-Agent Collaboration was the capability that generated the most discussion in the architecture community — and for good reason. For anyone who had spent time building single Bedrock agents and hitting the ceiling of what one agent can reliably orchestrate, the supervisor-plus-sub-agent model addressed a fundamental constraint. General availability at re:Invent gave teams something to actually build with immediately, and the months since have produced a clearer picture of where the pattern excels, where it creates new problems, and how to design multi-agent systems that remain operable in production rather than becoming distributed debugging nightmares.
This is not a tutorial rehash of the AWS getting-started guide. This is a practitioner assessment of production multi-agent architectures — the orchestration patterns that hold under load, the cost model that surprises teams who build without budgeting for token multiplication, the failure modes that do not appear until you push beyond ten active sessions, and the specific decisions that distinguish a maintainable multi-agent system from an impressive demo that cannot be diagnosed when it goes wrong.
Why Single Agents Hit a Ceiling — and What Multi-Agent Actually Solves
A single Bedrock Agent has a fixed context window, a single system prompt that must cover all operational domains, one set of action groups, and one knowledge base configuration. For narrow use cases — a customer support agent that answers product questions and raises tickets — this is entirely sufficient. The ceiling appears when you try to build agents that span multiple enterprise domains: an agent that needs to simultaneously reason about financial data, execute infrastructure changes, summarise regulatory documents, and draft customer communications.
The problem is not capability — Claude 3.5 Sonnet is capable of reasoning across all those domains. The problem is instruction coherence and context contamination. A system prompt long enough to make one agent expert in finance, infrastructure, compliance, and communications becomes internally contradictory and difficult for the model to follow consistently. Action groups balloon in size. The knowledge base contains documents from every domain, reducing retrieval precision for domain-specific queries. The agent’s effective quality degrades as the operational scope increases.
Multi-agent collaboration solves this through specialisation. Each sub-agent carries a focused system prompt, a domain-specific knowledge base, and a tight set of action groups relevant to its remit. The supervisor agent does not need deep domain knowledge — its role is orchestration: understanding the user’s intent, decomposing it into sub-tasks, routing those sub-tasks to appropriate specialists, synthesising the results. Separation of concern applied to LLM systems.
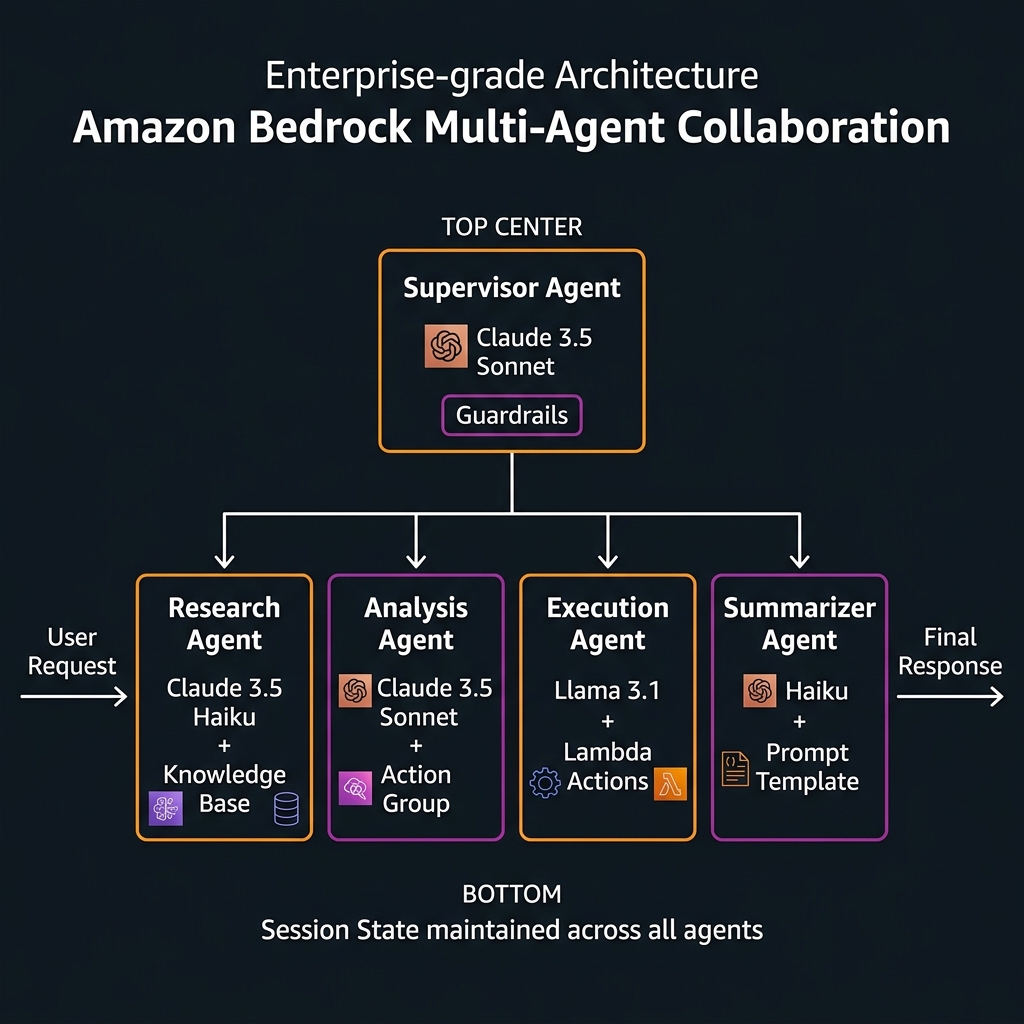
The Architecture: Supervisor, Sub-Agents, and Orchestration Strategies
Supervisor Orchestration Strategies
AWS supports two supervisor orchestration strategies, and the choice materially affects system behaviour:
SUPERVISOR strategy: The supervisor calls sub-agents, collects their outputs, and synthesises a final response. The supervisor sees all sub-agent outputs and makes the final determination of what to return to the user. This is appropriate when sub-agent outputs need to be combined or when the final response requires cross-domain reasoning over the collected results.
SUPERVISOR_ROUTER strategy: The supervisor routes the request to the single most appropriate sub-agent and returns that sub-agent’s response directly without further synthesis. This is appropriate for classification-style routing where the request clearly belongs to one domain and the sub-agent’s response is the complete answer. SUPERVISOR_ROUTER is faster and cheaper — it eliminates the supervisor’s synthesis step — and is underused because it is less prominently documented.
sequenceDiagram
participant U as User
participant S as Supervisor Agent
participant R as Research Agent
participant A as Analysis Agent
participant E as Execution Agent
U->>S: "Analyse Q4 sales, find anomalies, update forecast"
Note over S: Reasons: 3 distinct sub-tasks
S->>R: "Retrieve Q4 sales data and market benchmarks"
R-->>S: Sales data + benchmark context (KB retrieval)
S->>A: "Identify anomalies in: [sales data]"
A-->>S: Anomaly report with confidence scores
S->>E: "Update forecast model with: [anomalies]"
E-->>S: Execution confirmation + updated forecast ID
Note over S: Synthesises all results
S-->>U: Complete response: analysis + action confirmationSub-Agent Configuration: What Each Agent Owns
Every sub-agent in a multi-agent system is itself a full Bedrock Agent — it has its own foundation model selection, system prompt, knowledge base, action groups, and guardrails configuration. This independence is powerful: you can use Claude 3.5 Haiku for high-volume summary tasks (cost-optimised), Claude 3.5 Sonnet for complex reasoning tasks (quality-optimised), and Llama 3.1 for tasks where data must not leave specific trust boundaries — all within a single multi-agent workflow.
Sub-agents are registered with the supervisor via the Bedrock Agent console or API, where you provide a description that the supervisor uses to decide when to route tasks to that agent. The quality of this description is architecturally significant — poorly written sub-agent descriptions lead to mis-routing, where the supervisor sends tasks to the wrong specialist.
Building a Production Multi-Agent System on Bedrock
The following example implements a document intelligence pipeline: a supervisor routes document analysis requests to specialised sub-agents for extraction, classification, and summarisation. This pattern is representative of document-heavy enterprise use cases in legal, insurance, and healthcare.
import boto3
import json
import time
from typing import Optional
bedrock_agent = boto3.client("bedrock-agent", region_name="us-east-1")
bedrock_agent_rt = boto3.client("bedrock-agent-runtime", region_name="us-east-1")
# ──────────────────────────────────────────────────────────────────────────
# Step 1: Create specialised sub-agents
# Each sub-agent has focused responsibility and a domain-specific system prompt
# ──────────────────────────────────────────────────────────────────────────
def create_extraction_agent(guardrail_id: str) -> str:
"""Sub-agent: extracts structured data from unstructured documents."""
resp = bedrock_agent.create_agent(
agentName="doc-extraction-agent",
agentResourceRoleArn="arn:aws:iam::123456789012:role/BedrockAgentRole",
foundationModel="anthropic.claude-3-5-haiku-20241022-v1:0", # Fast, cost-effective
instruction="""You are a precise document data extraction specialist.
Your ONLY job is to extract specific structured data fields from documents.
For every document you receive:
1. Extract all named entities (parties, dates, amounts, identifiers)
2. Return a JSON object with extracted fields and confidence scores
3. Flag fields that are ambiguous or partially legible
You do NOT summarise, analyse, or make judgements.
You do NOT answer questions outside of data extraction.
Return ONLY structured JSON output.""",
guardrailConfiguration={
"guardrailIdentifier": guardrail_id,
"guardrailVersion": "DRAFT"
},
idleSessionTTLInSeconds=900
)
agent_id = resp["agent"]["agentId"]
# Prepare (compile) the agent
bedrock_agent.prepare_agent(agentId=agent_id)
return agent_id
def create_classification_agent(knowledge_base_id: str) -> str:
"""Sub-agent: classifies documents against regulatory taxonomy."""
resp = bedrock_agent.create_agent(
agentName="doc-classification-agent",
agentResourceRoleArn="arn:aws:iam::123456789012:role/BedrockAgentRole",
foundationModel="anthropic.claude-3-5-haiku-20241022-v1:0",
instruction="""You are a regulatory document classification specialist.
Classify documents against the regulatory taxonomy in your knowledge base.
For every document:
1. Identify the document type from the taxonomy
2. Assign primary and secondary classification codes
3. Flag any regulatory obligations triggered by the document type
4. Return classification with confidence score and supporting evidence
Do NOT extract data. Do NOT summarise content. Classification only.""",
)
agent_id = resp["agent"]["agentId"]
# Attach knowledge base (regulatory taxonomy)
bedrock_agent.associate_agent_knowledge_base(
agentId=agent_id,
agentVersion="DRAFT",
knowledgeBaseId=knowledge_base_id,
description="Regulatory document taxonomy and classification rules",
knowledgeBaseState="ENABLED"
)
bedrock_agent.prepare_agent(agentId=agent_id)
return agent_id
# ──────────────────────────────────────────────────────────────────────────
# Step 2: Create the Supervisor Agent and register sub-agents
# ──────────────────────────────────────────────────────────────────────────
def create_supervisor(extraction_agent_id: str, classification_agent_id: str,
extraction_alias: str, classification_alias: str) -> tuple[str, str]:
"""Creates supervisor and registers sub-agents as collaborators."""
resp = bedrock_agent.create_agent(
agentName="doc-intelligence-supervisor",
agentResourceRoleArn="arn:aws:iam::123456789012:role/BedrockAgentRole",
foundationModel="anthropic.claude-3-5-sonnet-20241022-v2:0", # Strong reasoning for orchestration
instruction="""You are a document intelligence orchestrator.
When you receive a document or document analysis request:
1. ALWAYS start by routing to the extraction agent to get structured data
2. THEN route to the classification agent to categorise the document
3. Synthesise both results into a comprehensive document intelligence report
4. If the user asks for only extraction OR only classification, route to one agent only
You coordinate specialists — you do not perform extraction or classification yourself.
Your output is a complete, structured report combining all specialist findings.""",
orchestrationType="DEFAULT" # SUPERVISOR strategy (combines sub-agent outputs)
)
supervisor_id = resp["agent"]["agentId"]
# Register sub-agents as collaborators
bedrock_agent.associate_agent_collaborator(
agentId=supervisor_id,
agentVersion="DRAFT",
agentDescriptor={
"aliasArn": f"arn:aws:bedrock:us-east-1:123456789012:agent-alias/{extraction_agent_id}/{extraction_alias}"
},
collaboratorName="ExtractionSpecialist",
collaborationInstruction="""Route here when you need to extract structured data fields
from a document. Handles named entities, dates, amounts, identifiers, parties.
Returns JSON with extracted fields and confidence scores.
Do NOT route here for classification, analysis, or summarisation.""",
relayConversationHistory="TO_COLLABORATOR" # Passes conversation context to sub-agent
)
bedrock_agent.associate_agent_collaborator(
agentId=supervisor_id,
agentVersion="DRAFT",
agentDescriptor={
"aliasArn": f"arn:aws:bedrock:us-east-1:123456789012:agent-alias/{classification_agent_id}/{classification_alias}"
},
collaboratorName="ClassificationSpecialist",
collaborationInstruction="""Route here when you need to classify a document against
the regulatory taxonomy. Returns document type, classification codes, and triggered obligations.
Do NOT route here for data extraction or content summarisation.""",
relayConversationHistory="TO_COLLABORATOR"
)
bedrock_agent.prepare_agent(agentId=supervisor_id)
# Create a named alias for the supervisor
alias_resp = bedrock_agent.create_agent_alias(
agentId=supervisor_id,
agentAliasName="production-v1"
)
return supervisor_id, alias_resp["agentAlias"]["agentAliasId"]
Invoking the Supervisor and Reading Traces
Invoking a multi-agent supervisor uses the same invoke_agent API as a single agent. The difference is in trace data: when enableTrace=True, the response stream includes trace events from both the supervisor’s reasoning and each sub-agent’s reasoning, giving full visibility into the orchestration chain. This trace visibility is the primary operational tool for debugging mis-routing and unexpected sub-agent selections.
import uuid
def invoke_supervisor_with_trace(
agent_id: str,
alias_id: str,
user_input: str,
document_content: Optional[str] = None
) -> dict:
"""
Invoke the supervisor agent and parse multi-agent trace for observability.
enableTrace=True is ESSENTIAL for production debugging of multi-agent systems.
"""
session_id = f"doc-intel-{uuid.uuid4().hex[:12]}"
# Optionally inject document content into the prompt
input_text = user_input
if document_content:
input_text = f"""Document to analyse:
---
{document_content}
---
{user_input}"""
response = bedrock_agent_rt.invoke_agent(
agentId=agent_id,
agentAliasId=alias_id,
sessionId=session_id,
inputText=input_text,
enableTrace=True
)
final_response = ""
trace_events = []
routing_decisions = []
for event in response.get("completion", []):
# Collect the final text response
if "chunk" in event:
final_response += event["chunk"]["bytes"].decode("utf-8")
# Parse trace events for observability
if "trace" in event:
trace = event["trace"]
# Routing decisions: which sub-agent was selected and why
if "orchestrationTrace" in trace.get("trace", {}):
orch = trace["trace"]["orchestrationTrace"]
if "invocationInput" in orch:
inv = orch["invocationInput"]
if inv.get("invocationType") == "AGENT_COLLABORATOR":
routing_decisions.append({
"collaborator": inv.get("agentCollaboratorInvocationInput", {}).get("agentCollaboratorName"),
"input_summary": str(inv)[:200]
})
trace_events.append({
"type": "orchestration",
"data": str(orch)[:300]
})
return {
"response": final_response,
"session_id": session_id,
"routing_decisions": routing_decisions, # Which sub-agents were called
"trace_event_count": len(trace_events),
"sub_agents_invoked": len(routing_decisions)
}
# Usage
result = invoke_supervisor_with_trace(
agent_id="SUPERVISOR_AGENT_ID",
alias_id="SUPERVISOR_ALIAS_ID",
user_input="Extract all parties and dates, then classify this contract",
document_content="SERVICE AGREEMENT dated January 15, 2026 between Acme Corp..."
)
print(f"Response: {result['response'][:500]}")
print(f"Sub-agents invoked: {result['sub_agents_invoked']}")
for rd in result['routing_decisions']:
print(f" → Routed to: {rd['collaborator']}")
The Cost Model: Understanding Token Multiplication
The cost implication of multi-agent architecture is the single most common surprise for teams coming from single-agent deployments. With a single agent, you pay for the user prompt + model output tokens. With a multi-agent supervisor system, each sub-agent invocation is a separate Bedrock API call with its own cost:
Supervisor turn 1: input tokens (user prompt + system prompt + action group definitions) + output tokens (routing decision). Sub-agent 1 call: input tokens (routed sub-task + sub-agent system prompt + knowledge base context) + output tokens (sub-agent response). Sub-agent 2 call: same structure. Supervisor synthesis: input tokens (supervisor system prompt + all sub-agent outputs) + output tokens (final response). A four-turn multi-agent interaction can easily consume 4-6x the tokens of an equivalent single-agent interaction.
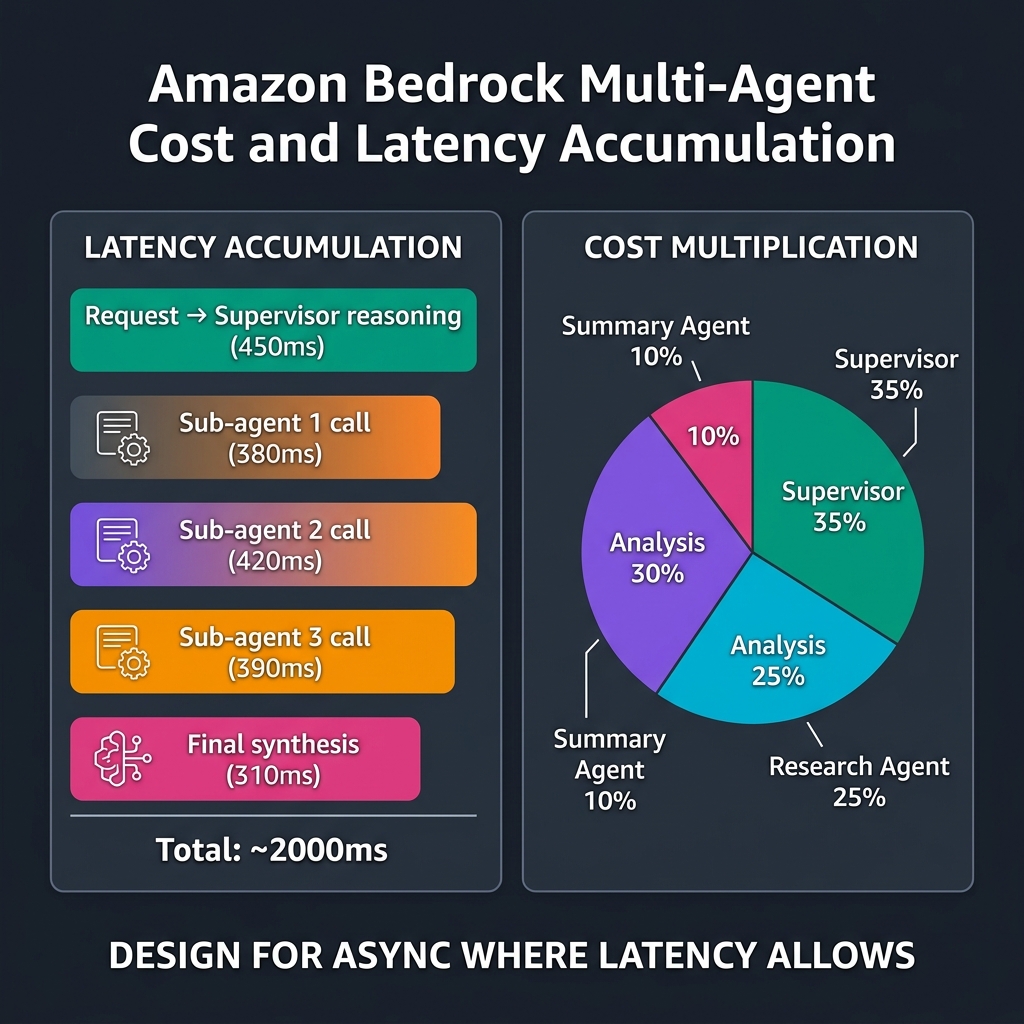
bedrock.agent.TokensProcessed per agent alias and set cost anomaly alerts before go-live.Cost Control Patterns
Model tiering: Use Claude 3.5 Haiku for high-frequency, well-scoped sub-agents (extraction, summarisation, classification) and Claude 3.5 Sonnet only for the supervisor and complex reasoning sub-agents. Haiku costs approximately 1/15th of Sonnet per token — in a system where extraction and classification agents handle 80% of sub-task volume, tiering reduces total cost by 50-60%.
SUPERVISOR_ROUTER for single-domain requests: If routing analysis shows that 60% of requests go to a single sub-agent with no synthesis required, use SUPERVISOR_ROUTER strategy for that request category. The router pattern eliminates the supervisor synthesis token cost entirely — the sub-agent’s response is returned directly.
Async patterns for latency-tolerant workflows: Multi-agent orchestration where sub-agents run sequentially adds latency proportional to the number of sub-agent hops. For document processing pipelines, batch jobs, and nightly analysis workflows that do not require real-time responses, invoke the supervisor asynchronously via Lambda with results stored to S3 and delivered via SNS notification. This decouples cost from user-perceived latency and enables much larger agent topologies.
Failure Modes: What Goes Wrong in Production
Supervisor Mis-Routing
The most common failure mode: the supervisor calls the wrong sub-agent for a task, the sub-agent returns an irrelevant or error response, and the supervisor either retries (consuming more tokens) or synthesises a confused final response. Mis-routing happens when sub-agent descriptions overlap in scope — when the supervisor cannot clearly determine which specialist owns a given sub-task from the descriptions alone.
Diagnose mis-routing by parsing the agentCollaboratorInvocationInput trace events from production sessions. Implement a CloudWatch Logs Insights query that extracts which sub-agents were called per session, then compare against the expected routing for each request type. Routing accuracy below 90% indicates description quality issues.
Session State Accumulation
Each sub-agent call within a session accumulates conversation history in the session state, which is passed forward (when relayConversationHistory=TO_COLLABORATOR). For long sessions with many sub-agent hops, the growing context window can push individual sub-agent calls against their context limit. Monitor session length in production and implement session summarisation for workflows exceeding ten sub-agent interactions.
Sub-Agent Timeout Cascades
If a sub-agent times out (default session TTL exceeded, or a Lambda action group call fails), the supervisor receives an error signal. The supervisor’s behaviour on receiving sub-agent errors depends on its system prompt — if not explicitly instructed to handle partial failures, the supervisor may attempt to synthesise a response from incomplete information without flagging the failure to the user. Always include explicit failure handling guidance in the supervisor system prompt.
# Supervisor system prompt with explicit failure handling
SUPERVISOR_INSTRUCTION = """You are a document intelligence orchestrator.
When coordinating sub-agents:
1. Always route extraction before classification (extraction output informs classification)
2. If a sub-agent returns an error or empty response, do NOT attempt to continue with other sub-agents
3. On sub-agent failure, immediately return to the user with:
- Which specialist failed
- What partial information was collected before the failure
- A recommended retry action
CRITICAL: Never fabricate or infer data that a sub-agent should have provided.
If extraction fails, the classification step must be skipped — do not proceed
with classification on incomplete extraction data.
Output format: Always structure your final response as JSON with keys:
- extraction_complete (bool)
- classification_complete (bool)
- extracted_data (object or null)
- classification_result (object or null)
- errors (array of error descriptions, empty if none)
- confidence_score (0.0-1.0 overall pipeline confidence)"""
Single Agent or Multi-Agent: The Decision Framework
Multi-agent adds orchestration complexity, token cost, and operational surface. It is not the right answer for every Bedrock use case. Apply this framework:
flowchart TD
A["Designing a Bedrock Agent system"] --> B{"Does the task span
multiple distinct domains?"}
B -->|"No - single domain"| C["Single Agent
Simpler, cheaper, easier to debug"]
B -->|"Yes - multiple domains"| D{"Can one system prompt
cover all domains coherently?"}
D -->|"Yes - under 1500 tokens
clear, non-contradictory"| C
D -->|"No - prompt becomes
convoluted or contradictory"| E{"Is real-time response
required (< 3s)?"}
E -->|"Yes"| F{"More than 2 sub-agents
needed sequentially?"}
F -->|"Yes"| G["Redesign: parallel sub-agent
calls or async pattern"]
F -->|"No"| H["Multi-Agent (2 sub-agents)
Supervisor + 2 specialists"]
E -->|"No - async acceptable"| I["Multi-Agent
Up to 5 sub-agents
Async invocation via Lambda"]
G --> J["Multi-Agent parallel
or Step Functions orchestration"]The latency constraint is real and often underestimated. Each sequential sub-agent call adds 300-800ms of LLM inference time. A supervisor calling three sub-agents sequentially adds 1-2.5 seconds to response latency before the supervisor’s own synthesis. For conversational UIs with sub-3-second response expectations, limit sequential sub-agent hops to two and explore parallel invocation for independent sub-tasks.
Parallel Sub-Agent Invocation via Step Functions
When multiple sub-agents can execute independently (their inputs do not depend on each other’s outputs), invoke them in parallel using AWS Step Functions or Lambda concurrency rather than relying on the supervisor to call them sequentially. This pattern requires stepping outside the Bedrock Multi-Agent API and orchestrating at the application layer, but for latency-critical workflows it is the correct architectural choice.
import boto3
import asyncio
from concurrent.futures import ThreadPoolExecutor
bedrock_rt = boto3.client("bedrock-agent-runtime", region_name="us-east-1")
def invoke_agent_sync(agent_id: str, alias_id: str, session_id: str, text: str) -> str:
"""Synchronous single-agent invocation for use in thread pool."""
response = bedrock_rt.invoke_agent(
agentId=agent_id, agentAliasId=alias_id,
sessionId=session_id, inputText=text, enableTrace=False
)
result = ""
for event in response.get("completion", []):
if "chunk" in event:
result += event["chunk"]["bytes"].decode("utf-8")
return result
async def invoke_parallel_agents(document: str, session_prefix: str) -> dict:
"""
Invoke independent sub-agents in parallel using thread pool.
Use when sub-agent inputs don't depend on each other's outputs.
Reduces multi-agent latency from sum(hops) to max(hop) + synthesis.
"""
EXTRACTION_AGENT = ("EXTRACT_AGENT_ID", "EXTRACT_ALIAS_ID")
CLASSIFICATION_AGENT = ("CLASS_AGENT_ID", "CLASS_ALIAS_ID")
SENTIMENT_AGENT = ("SENTIMENT_AGENT_ID", "SENTIMENT_ALIAS_ID")
loop = asyncio.get_event_loop()
with ThreadPoolExecutor(max_workers=3) as executor:
futures = {
"extraction": loop.run_in_executor(
executor, invoke_agent_sync,
*EXTRACTION_AGENT, f"{session_prefix}-ext", document
),
"classification": loop.run_in_executor(
executor, invoke_agent_sync,
*CLASSIFICATION_AGENT, f"{session_prefix}-cls", document
),
"sentiment": loop.run_in_executor(
executor, invoke_agent_sync,
*SENTIMENT_AGENT, f"{session_prefix}-sent", document
),
}
results = {}
for name, future in futures.items():
try:
results[name] = await future
except Exception as e:
results[name] = f"ERROR: {str(e)}"
return results # All three results available after max(latency_1, latency_2, latency_3)
Observability Strategy for Multi-Agent Systems
The operational challenge of multi-agent systems is that failures can originate from any agent in the topology, and the final response may mask the origin of the failure. A structured observability strategy is non-negotiable for production deployments.
Enable CloudTrail logging for all Bedrock Agent invocations — this provides an audit trail of which agents were called, when, and by which IAM principal. Enable model invocation logging in the Bedrock console for all agent aliases — this captures prompt/response pairs for debugging quality issues. Add sessionId as a structured log field in your application layer, and correlate application logs, Bedrock invocation logs, and CloudTrail records using the session ID as the join key.
Key Takeaways
- Multi-agent solves prompt coherence, not capability gaps — use it when a single system prompt becomes contradictory across domains, not simply because a task is complex; a well-scoped single agent with good action groups handles most enterprise use cases
- Sub-agent description quality is your routing quality — invest time in precise, boundary-explicit sub-agent descriptions; ambiguous descriptions are the primary cause of mis-routing in production systems
- Token costs multiply with sub-agent hops — model tier your sub-agents aggressively (Haiku for extraction/classification, Sonnet for the supervisor) and audit token consumption per agent alias before production launch
- SUPERVISOR_ROUTER eliminates synthesis cost for single-domain requests — use it when routing analysis shows the majority of requests go to one sub-agent with no cross-domain synthesis required
- Parallel invocation for independent sub-tasks — when sub-agents do not depend on each other’s outputs, invoke them concurrently via Step Functions or async Lambda rather than sequentially through the supervisor, reducing latency from sum to max
- Guardrails do not propagate from supervisor to sub-agents — configure Guardrails independently on every agent in the topology; this is a compliance gap that auditors specifically check in regulated industry deployments
- Session trace parsing is your primary debugging tool — parse
agentCollaboratorInvocationInputtrace events to build routing accuracy dashboards; this data drives sub-agent description improvements over time
Glossary
- Bedrock Multi-Agent Collaboration
- An Amazon Bedrock capability where a Supervisor Agent decomposes complex requests and orchestrates multiple specialised Sub-Agents, each with its own foundation model, knowledge base, action groups, and guardrails configuration.
- Supervisor Agent
- The orchestrating agent in a multi-agent topology. Receives the user request, reasons about decomposition, routes sub-tasks to specialised collaborators, and synthesises a final response from their outputs.
- Sub-Agent (Collaborator)
- A fully configured Bedrock Agent registered as a collaborator with a supervisor. Executes domain-specific sub-tasks and returns results to the supervisor for synthesis. Each sub-agent is billed independently.
- SUPERVISOR strategy
- An orchestration mode where the supervisor calls one or more sub-agents, collects all their outputs, and synthesises a final response. Appropriate when cross-domain reasoning over combined results is required.
- SUPERVISOR_ROUTER strategy
- An orchestration mode where the supervisor identifies the single most appropriate sub-agent and returns its response directly without synthesis. Lower latency and cost; suitable when requests clearly belong to one domain.
- relayConversationHistory
- A collaborator configuration parameter that controls whether conversation history from the supervisor session is passed to sub-agents. ‘TO_COLLABORATOR’ provides context; ‘DISABLED’ keeps sub-agents stateless.
- Mis-routing
- A failure mode where the supervisor calls the wrong sub-agent for a given sub-task, typically caused by overlapping or ambiguous sub-agent descriptions. Diagnosable via agentCollaboratorInvocationInput trace events.
- Token Multiplication
- The cost pattern in multi-agent systems where each sub-agent invocation generates independent token charges for its own input (system prompt, context, sub-task) and output, resulting in total token costs 3-6x higher than equivalent single-agent interactions.
- agentCollaboratorInvocationInput
- A Bedrock trace event type that records which sub-agent was selected and what input was routed to it. The primary observability signal for auditing routing decisions and debugging mis-routing.
- Model Tiering
- The practice of using less expensive models (e.g., Claude 3.5 Haiku) for high-volume, well-scoped sub-agents and more capable models (e.g., Claude 3.5 Sonnet) for orchestration and complex reasoning, reducing overall token costs.
- Guardrails Propagation
- A common misconception: Bedrock Guardrails configured on a supervisor agent do NOT automatically apply to sub-agent invocations. Each sub-agent must have its own Guardrails configuration for consistent safety and compliance enforcement.
References & Further Reading
- → Amazon Bedrock — Multi-Agent Collaboration— Official documentation covering supervisor setup, collaborator registration, and orchestration strategies
- → Bedrock Multi-Agent — Orchestration Strategies— SUPERVISOR vs SUPERVISOR_ROUTER strategy comparison and configuration reference
- → Bedrock Multi-Agent — Cost Considerations— Token billing model for supervisor and sub-agent invocations; cost optimisation guidance
- → Bedrock Runtime API — InvokeAgent Reference— Complete API reference for agent invocation including trace parameters and response streaming
- → Bedrock Agents — Trace and Logging— Trace event structure for multi-agent orchestration, including collaborator invocation traces
- → Bedrock Guardrails — Agent Configuration— Applying guardrails to agents; clarification that supervisor guardrails do not propagate to sub-agents
- → AWS ML Blog — Build Multi-Agent Systems with Amazon Bedrock— AWS engineering deep dive on supervisor-collaborator topology and production patterns
- → GitHub — Amazon Bedrock Agent Samples— Official AWS sample implementations for single and multi-agent Bedrock patterns
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.