Introduction: Processing documents with LLMs unlocks powerful capabilities: extracting structured data from unstructured text, summarizing lengthy reports, answering questions about document content, and transforming documents between formats. However, effective document processing requires more than just sending text to an LLM—it demands careful parsing, intelligent chunking, and strategic prompting. This guide covers practical document processing patterns: parsing various formats, chunking strategies for context windows, extraction and summarization techniques, and production-ready pipelines for processing documents at scale.
- Part 1: From PDFs to structured data
- Part 2 (this article): Enterprise parsing, chunking, and extraction
Enterprise Document Extraction
Enterprise document processing handles diverse document types at scale. This architecture shows how extraction pipelines handle complex documents.
flowchart TB
subgraph Intake["Document Intake"]
S3[S3 Bucket]
API[Upload API]
EM[Email Parser]
end
subgraph Classification["Classification"]
DC[Doc Classifier]
TE[Type Extractor]
end
subgraph Extraction["Extraction Pipelines"]
INV[Invoice Pipeline]
CON[Contract Pipeline]
RES[Resume Pipeline]
end
subgraph Validation["Validation"]
SV[Schema Validator]
BC[Business Rules]
HV[Human Review]
end
subgraph Output["Output"]
DB[(Database)]
WF[Workflow]
end
S3 --> DC
API --> DC
EM --> DC
DC --> TE
TE --> INV
TE --> CON
TE --> RES
INV --> SV
CON --> SV
RES --> SV
SV --> BC
BC -->|Pass| DB
BC -->|Fail| HV
HV --> DB
DB --> WF
style S3 fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style API fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style EM fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style DC fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style TE fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style INV fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style CON fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style RES fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style SV fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style BC fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style HV fill:#FCE4EC,stroke:#F48FB1,stroke-width:2px,color:#AD1457
style DB fill:#ECEFF1,stroke:#90A4AE,stroke-width:2px,color:#455A64
style WF fill:#ECEFF1,stroke:#90A4AE,stroke-width:2px,color:#455A64
Figure 1: Enterprise Document Extraction Architecture
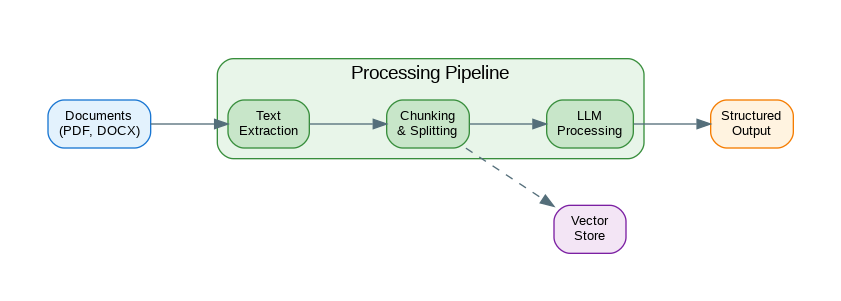
Document Parsing
The following code implements document parsing. Key aspects include proper error handling and clean separation of concerns.
from dataclasses import dataclass, field
from typing import Any, Optional
from enum import Enum
from pathlib import Path
class DocumentType(Enum):
PDF = "pdf"
DOCX = "docx"
HTML = "html"
MARKDOWN = "markdown"
TXT = "txt"
CSV = "csv"
@dataclass
class ParsedDocument:
"""A parsed document with extracted content."""
content: str
doc_type: DocumentType
metadata: dict = field(default_factory=dict)
pages: list[str] = field(default_factory=list)
tables: list[dict] = field(default_factory=list)
images: list[dict] = field(default_factory=list)
class DocumentParser:
"""Parse various document formats."""
def parse(self, file_path: str) -> ParsedDocument:
"""Parse document based on file extension."""
path = Path(file_path)
extension = path.suffix.lower()
parsers = {
".pdf": self._parse_pdf,
".docx": self._parse_docx,
".html": self._parse_html,
".htm": self._parse_html,
".md": self._parse_markdown,
".txt": self._parse_text,
".csv": self._parse_csv,
}
parser = parsers.get(extension)
if not parser:
raise ValueError(f"Unsupported file type: {extension}")
return parser(file_path)
def _parse_pdf(self, file_path: str) -> ParsedDocument:
"""Parse PDF document."""
import fitz # PyMuPDF
doc = fitz.open(file_path)
pages = []
tables = []
images = []
for page_num, page in enumerate(doc):
# Extract text
text = page.get_text()
pages.append(text)
# Extract images
for img_index, img in enumerate(page.get_images()):
images.append({
"page": page_num,
"index": img_index,
"xref": img[0]
})
return ParsedDocument(
content="\n\n".join(pages),
doc_type=DocumentType.PDF,
metadata={
"page_count": len(pages),
"title": doc.metadata.get("title", ""),
"author": doc.metadata.get("author", "")
},
pages=pages,
images=images
)
def _parse_docx(self, file_path: str) -> ParsedDocument:
"""Parse Word document."""
from docx import Document
doc = Document(file_path)
paragraphs = []
tables = []
for para in doc.paragraphs:
if para.text.strip():
paragraphs.append(para.text)
for table in doc.tables:
table_data = []
for row in table.rows:
row_data = [cell.text for cell in row.cells]
table_data.append(row_data)
tables.append({"data": table_data})
return ParsedDocument(
content="\n\n".join(paragraphs),
doc_type=DocumentType.DOCX,
metadata={"paragraph_count": len(paragraphs)},
tables=tables
)
def _parse_html(self, file_path: str) -> ParsedDocument:
"""Parse HTML document."""
from bs4 import BeautifulSoup
with open(file_path, 'r', encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'html.parser')
# Remove script and style elements
for element in soup(['script', 'style', 'nav', 'footer']):
element.decompose()
text = soup.get_text(separator='\n', strip=True)
# Extract tables
tables = []
for table in soup.find_all('table'):
rows = []
for row in table.find_all('tr'):
cells = [cell.get_text(strip=True) for cell in row.find_all(['td', 'th'])]
rows.append(cells)
tables.append({"data": rows})
return ParsedDocument(
content=text,
doc_type=DocumentType.HTML,
metadata={"title": soup.title.string if soup.title else ""},
tables=tables
)
def _parse_markdown(self, file_path: str) -> ParsedDocument:
"""Parse Markdown document."""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
return ParsedDocument(
content=content,
doc_type=DocumentType.MARKDOWN,
metadata={}
)
def _parse_text(self, file_path: str) -> ParsedDocument:
"""Parse plain text document."""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
return ParsedDocument(
content=content,
doc_type=DocumentType.TXT,
metadata={}
)
def _parse_csv(self, file_path: str) -> ParsedDocument:
"""Parse CSV document."""
import csv
with open(file_path, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
rows = list(reader)
# Convert to text representation
text_rows = [", ".join(row) for row in rows]
return ParsedDocument(
content="\n".join(text_rows),
doc_type=DocumentType.CSV,
metadata={"row_count": len(rows)},
tables=[{"data": rows}]
)Chunking Strategies
Chunking splits documents into manageable pieces while preserving context. The strategy you choose significantly impacts retrieval quality.
from dataclasses import dataclass
from typing import Callable, Optional
import re
@dataclass
class Chunk:
"""A chunk of document content."""
content: str
index: int
metadata: dict = None
@property
def token_estimate(self) -> int:
"""Rough token estimate (4 chars per token)."""
return len(self.content) // 4
class TextChunker:
"""Split text into chunks."""
def __init__(
self,
chunk_size: int = 1000,
chunk_overlap: int = 200,
length_function: Callable[[str], int] = None
):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.length_function = length_function or len
def chunk(self, text: str) -> list[Chunk]:
"""Split text into overlapping chunks."""
chunks = []
start = 0
index = 0
while start < len(text):
end = start + self.chunk_size
# Find a good break point
if end < len(text):
# Try to break at paragraph
break_point = text.rfind('\n\n', start, end)
if break_point == -1:
# Try sentence break
break_point = text.rfind('. ', start, end)
if break_point == -1:
# Try word break
break_point = text.rfind(' ', start, end)
if break_point > start:
end = break_point + 1
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append(Chunk(
content=chunk_text,
index=index,
metadata={"start": start, "end": end}
))
index += 1
start = end - self.chunk_overlap
return chunks
class SemanticChunker:
"""Chunk based on semantic boundaries."""
def __init__(
self,
max_chunk_size: int = 1000,
min_chunk_size: int = 100
):
self.max_chunk_size = max_chunk_size
self.min_chunk_size = min_chunk_size
def chunk(self, text: str) -> list[Chunk]:
"""Split at semantic boundaries."""
# Split by headers and sections
sections = self._split_by_headers(text)
chunks = []
index = 0
for section in sections:
if len(section) <= self.max_chunk_size:
if len(section) >= self.min_chunk_size:
chunks.append(Chunk(content=section, index=index))
index += 1
else:
# Further split large sections
sub_chunks = self._split_by_paragraphs(section)
for sub in sub_chunks:
chunks.append(Chunk(content=sub, index=index))
index += 1
return chunks
def _split_by_headers(self, text: str) -> list[str]:
"""Split text by markdown-style headers."""
# Match headers (# Header, ## Header, etc.)
pattern = r'(?=^#{1,6}\s)'
sections = re.split(pattern, text, flags=re.MULTILINE)
return [s.strip() for s in sections if s.strip()]
def _split_by_paragraphs(self, text: str) -> list[str]:
"""Split text by paragraphs, respecting max size."""
paragraphs = text.split('\n\n')
chunks = []
current_chunk = ""
for para in paragraphs:
if len(current_chunk) + len(para) <= self.max_chunk_size:
current_chunk += para + "\n\n"
else:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = para + "\n\n"
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
class RecursiveChunker:
"""Recursively split using multiple separators."""
SEPARATORS = ["\n\n", "\n", ". ", " ", ""]
def __init__(
self,
chunk_size: int = 1000,
chunk_overlap: int = 200
):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def chunk(self, text: str) -> list[Chunk]:
"""Recursively split text."""
chunks = self._split_recursive(text, self.SEPARATORS)
return [
Chunk(content=c, index=i)
for i, c in enumerate(chunks)
]
def _split_recursive(
self,
text: str,
separators: list[str]
) -> list[str]:
"""Recursively split with fallback separators."""
if not separators:
return [text]
separator = separators[0]
remaining_separators = separators[1:]
if not separator:
# Character-level split
return [text[i:i + self.chunk_size] for i in range(0, len(text), self.chunk_size - self.chunk_overlap)]
splits = text.split(separator)
chunks = []
current_chunk = ""
for split in splits:
if len(current_chunk) + len(split) <= self.chunk_size:
current_chunk += split + separator
else:
if current_chunk:
chunks.append(current_chunk.strip())
if len(split) > self.chunk_size:
# Recursively split with next separator
sub_chunks = self._split_recursive(split, remaining_separators)
chunks.extend(sub_chunks)
current_chunk = ""
else:
current_chunk = split + separator
if current_chunk:
chunks.append(current_chunk.strip())
return chunksLLM-Based Extraction
Parsing transforms raw input into structured data. This implementation handles common edge cases and malformed inputs gracefully.
from dataclasses import dataclass
from typing import Any, Optional
import json
@dataclass
class ExtractionSchema:
"""Schema for structured extraction."""
fields: list[dict]
description: str = ""
class DocumentExtractor:
"""Extract structured data from documents."""
EXTRACTION_PROMPT = """Extract the following information from the document.
Fields to extract:
{fields}
Document:
{document}
Return the extracted information as JSON with the field names as keys.
If a field is not found, use null."""
def __init__(self, client: Any, model: str = "gpt-4o-mini"):
self.client = client
self.model = model
async def extract(
self,
document: str,
schema: ExtractionSchema
) -> dict:
"""Extract structured data from document."""
fields_desc = "\n".join([
f"- {f['name']}: {f.get('description', f['name'])}"
for f in schema.fields
])
prompt = self.EXTRACTION_PROMPT.format(
fields=fields_desc,
document=document[:8000] # Truncate for context
)
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
async def extract_from_chunks(
self,
chunks: list[Chunk],
schema: ExtractionSchema
) -> list[dict]:
"""Extract from multiple chunks and merge."""
import asyncio
tasks = [
self.extract(chunk.content, schema)
for chunk in chunks
]
results = await asyncio.gather(*tasks)
return self._merge_extractions(results, schema)
def _merge_extractions(
self,
extractions: list[dict],
schema: ExtractionSchema
) -> dict:
"""Merge extractions from multiple chunks."""
merged = {}
for field in schema.fields:
name = field['name']
field_type = field.get('type', 'string')
values = [e.get(name) for e in extractions if e.get(name)]
if not values:
merged[name] = None
elif field_type == 'list':
# Combine lists
merged[name] = []
for v in values:
if isinstance(v, list):
merged[name].extend(v)
else:
merged[name].append(v)
else:
# Take first non-null value
merged[name] = values[0]
return merged
class DocumentSummarizer:
"""Summarize documents using LLM."""
SUMMARY_PROMPT = """Summarize the following document in {style} style.
Keep the summary under {max_words} words.
Document:
{document}
Summary:"""
def __init__(self, client: Any, model: str = "gpt-4o-mini"):
self.client = client
self.model = model
async def summarize(
self,
document: str,
style: str = "concise",
max_words: int = 200
) -> str:
"""Summarize a document."""
prompt = self.SUMMARY_PROMPT.format(
style=style,
max_words=max_words,
document=document[:8000]
)
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def summarize_long_document(
self,
chunks: list[Chunk],
style: str = "concise",
max_words: int = 500
) -> str:
"""Summarize long document using map-reduce."""
import asyncio
# Map: Summarize each chunk
chunk_summaries = await asyncio.gather(*[
self.summarize(chunk.content, style="brief", max_words=100)
for chunk in chunks
])
# Reduce: Combine summaries
combined = "\n\n".join(chunk_summaries)
return await self.summarize(combined, style=style, max_words=max_words)Document Q&A
The following code implements document q&a. Key aspects include proper error handling and clean separation of concerns.
from dataclasses import dataclass
from typing import Any, Optional
@dataclass
class QAResult:
"""Result from document Q&A."""
answer: str
confidence: float
source_chunks: list[Chunk]
citations: list[str]
class DocumentQA:
"""Answer questions about documents."""
QA_PROMPT = """Answer the question based on the provided context.
If the answer is not in the context, say "I cannot find this information in the document."
Context:
{context}
Question: {question}
Answer:"""
def __init__(
self,
client: Any,
model: str = "gpt-4o",
embedding_client: Any = None
):
self.client = client
self.model = model
self.embedding_client = embedding_client
async def answer(
self,
question: str,
chunks: list[Chunk],
top_k: int = 5
) -> QAResult:
"""Answer question using document chunks."""
# Find relevant chunks
relevant_chunks = await self._find_relevant_chunks(
question, chunks, top_k
)
# Build context
context = "\n\n---\n\n".join([
f"[Section {c.index + 1}]\n{c.content}"
for c in relevant_chunks
])
prompt = self.QA_PROMPT.format(
context=context,
question=question
)
response = await self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}]
)
answer = response.choices[0].message.content
return QAResult(
answer=answer,
confidence=0.8, # Could be calculated from response
source_chunks=relevant_chunks,
citations=[f"Section {c.index + 1}" for c in relevant_chunks]
)
async def _find_relevant_chunks(
self,
question: str,
chunks: list[Chunk],
top_k: int
) -> list[Chunk]:
"""Find chunks most relevant to question."""
if self.embedding_client:
# Use semantic search
return await self._semantic_search(question, chunks, top_k)
else:
# Use keyword matching
return self._keyword_search(question, chunks, top_k)
async def _semantic_search(
self,
question: str,
chunks: list[Chunk],
top_k: int
) -> list[Chunk]:
"""Find relevant chunks using embeddings."""
import numpy as np
# Get question embedding
q_response = await self.embedding_client.embeddings.create(
model="text-embedding-3-small",
input=question
)
q_embedding = np.array(q_response.data[0].embedding)
# Get chunk embeddings
chunk_texts = [c.content for c in chunks]
c_response = await self.embedding_client.embeddings.create(
model="text-embedding-3-small",
input=chunk_texts
)
c_embeddings = np.array([d.embedding for d in c_response.data])
# Calculate similarities
similarities = np.dot(c_embeddings, q_embedding)
# Get top k
top_indices = np.argsort(similarities)[::-1][:top_k]
return [chunks[i] for i in top_indices]
def _keyword_search(
self,
question: str,
chunks: list[Chunk],
top_k: int
) -> list[Chunk]:
"""Find relevant chunks using keyword matching."""
question_words = set(question.lower().split())
scored_chunks = []
for chunk in chunks:
chunk_words = set(chunk.content.lower().split())
overlap = len(question_words & chunk_words)
scored_chunks.append((chunk, overlap))
scored_chunks.sort(key=lambda x: x[1], reverse=True)
return [c for c, _ in scored_chunks[:top_k]]Production Document Service
The following implementation demonstrates a production-ready approach to production document service. This code includes proper error handling, logging, and configuration management.
from fastapi import FastAPI, HTTPException, UploadFile, File
from pydantic import BaseModel
from typing import Optional
import tempfile
import os
app = FastAPI()
# Initialize components
parser = DocumentParser()
chunker = RecursiveChunker()
extractor = None # Initialize with actual client
summarizer = None
qa_system = None
# Document storage
documents: dict[str, ParsedDocument] = {}
document_chunks: dict[str, list[Chunk]] = {}
class ExtractRequest(BaseModel):
doc_id: str
fields: list[dict]
class SummarizeRequest(BaseModel):
doc_id: str
style: str = "concise"
max_words: int = 200
class QARequest(BaseModel):
doc_id: str
question: str
@app.post("/v1/documents/upload")
async def upload_document(file: UploadFile = File(...)):
"""Upload and parse a document."""
# Save to temp file
with tempfile.NamedTemporaryFile(delete=False, suffix=file.filename) as tmp:
content = await file.read()
tmp.write(content)
tmp_path = tmp.name
try:
# Parse document
parsed = parser.parse(tmp_path)
# Chunk document
chunks = chunker.chunk(parsed.content)
# Generate ID
doc_id = str(hash(file.filename + str(len(content))))
# Store
documents[doc_id] = parsed
document_chunks[doc_id] = chunks
return {
"doc_id": doc_id,
"filename": file.filename,
"doc_type": parsed.doc_type.value,
"chunk_count": len(chunks),
"metadata": parsed.metadata
}
finally:
os.unlink(tmp_path)
@app.post("/v1/documents/extract")
async def extract_from_document(request: ExtractRequest):
"""Extract structured data from document."""
if request.doc_id not in documents:
raise HTTPException(404, "Document not found")
chunks = document_chunks[request.doc_id]
schema = ExtractionSchema(fields=request.fields)
result = await extractor.extract_from_chunks(chunks, schema)
return {"doc_id": request.doc_id, "extracted": result}
@app.post("/v1/documents/summarize")
async def summarize_document(request: SummarizeRequest):
"""Summarize a document."""
if request.doc_id not in documents:
raise HTTPException(404, "Document not found")
chunks = document_chunks[request.doc_id]
summary = await summarizer.summarize_long_document(
chunks,
style=request.style,
max_words=request.max_words
)
return {"doc_id": request.doc_id, "summary": summary}
@app.post("/v1/documents/qa")
async def question_answer(request: QARequest):
"""Answer question about document."""
if request.doc_id not in documents:
raise HTTPException(404, "Document not found")
chunks = document_chunks[request.doc_id]
result = await qa_system.answer(request.question, chunks)
return {
"doc_id": request.doc_id,
"question": request.question,
"answer": result.answer,
"citations": result.citations
}
@app.get("/v1/documents/{doc_id}")
async def get_document(doc_id: str):
"""Get document metadata."""
if doc_id not in documents:
raise HTTPException(404, "Document not found")
doc = documents[doc_id]
return {
"doc_id": doc_id,
"doc_type": doc.doc_type.value,
"chunk_count": len(document_chunks[doc_id]),
"metadata": doc.metadata
}
@app.get("/health")
async def health():
return {"status": "healthy"}References
- LangChain Document Loaders: https://python.langchain.com/docs/modules/data_connection/document_loaders/
- LlamaIndex Document Processing: https://docs.llamaindex.ai/en/stable/module_guides/loading/
- Unstructured Library: https://unstructured.io/
- PyMuPDF: https://pymupdf.readthedocs.io/
Conclusion
Document processing with LLMs requires a systematic approach. Start with robust parsing that handles various formats—PDFs, Word documents, HTML, and plain text each have unique challenges. Chunking strategies must balance context preservation with token limits—semantic chunking preserves meaning better than fixed-size splits. Use recursive chunking with multiple separators for robust handling of diverse document structures. Extraction benefits from clear schemas and multi-chunk aggregation for long documents. Summarization works best with map-reduce patterns that summarize chunks individually before combining. Document Q&A requires effective retrieval to find relevant chunks before generating answers. Build pipelines that handle errors gracefully and scale to process documents in parallel. The goal is transforming unstructured documents into structured, queryable knowledge.
Key Takeaways
- ✅ Parse before processing – Clean text extraction is essential for quality
- ✅ Chunk intelligently – Semantic chunking preserves context
- ✅ Validate extractions – LLM output needs verification for business-critical data
- ✅ Handle failures gracefully – Document processing is inherently noisy
- ✅ Pipeline with care – Each stage can degrade quality if not monitored
Conclusion
LLM-powered document processing transforms unstructured documents into structured, actionable data. Success requires thoughtful pipeline design: robust parsing, intelligent chunking, validated extraction, and comprehensive error handling.
References
- Unstructured.io – Document parsing library
- LlamaIndex Document Loaders
- Document Understanding with Multimodal Models
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.